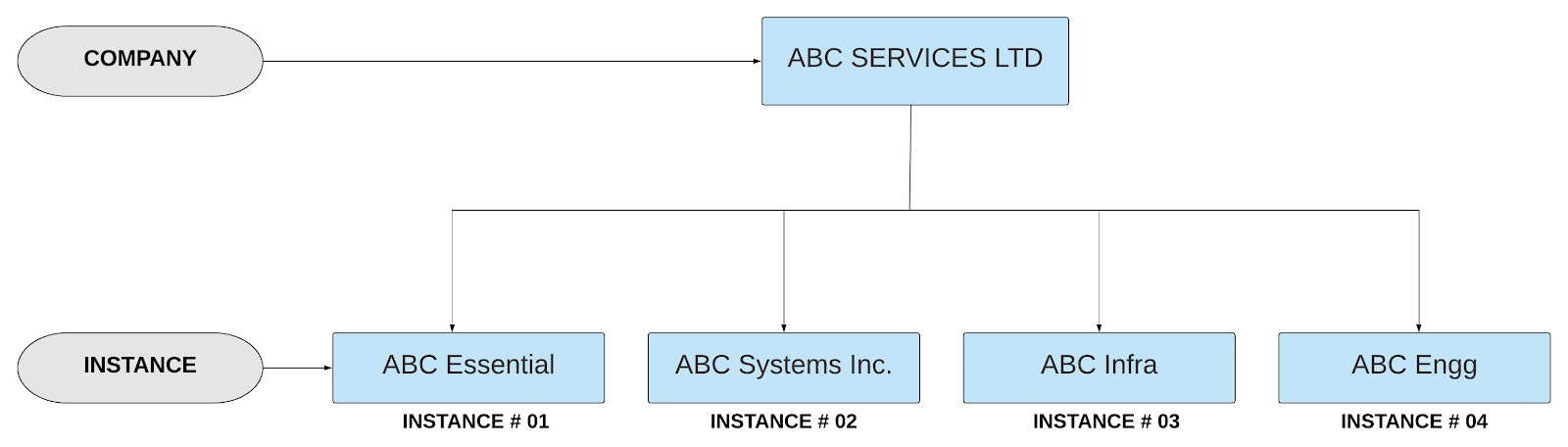
I’m trying to get Adoption Explorer setup and working, but so far no luck.
One question I have that I cannot seem to find in the documention - what do you do if your Weekly Time Series data has more than one Unique ID?
For example, I have a usage data file that contains usage metrics by Company AND Usage Type, so for example if Gainsight were my customer I might have:
Company Name ID Date Usage Type Total
GAINSIGHT 33455 11/12/2019 Logins 365
GAINSIGHT 33455 11/12/2019 Punches 724
GAINSIGHT 33455 11/19/2019 Logins 398
GAINSIGHT 33455 11/19/2019 Punches 772
I want to make sure that I’m upserting on the ID, Date and Usage Type.
When importing the data via S3 Connector, I have the option of selecting multiple key fields:
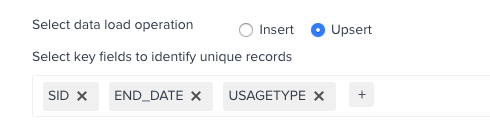
But I can’t seem to figure out how to do this in an Adoption Explorer project.