I need the ability to suppress the creation of CTA "B" if the customer already has CTA "A" opened.
In our use case, the customer lifecycle is fairly linear, so until issue "A" is cleared up, of course issue "B" is going to be an issue because "B" is dependent on "A." (In real terms, if the customer hasn't loaded their users, for example, of course there is going to be an issue with their usage of the product.) Our CSMs do not want to see CTA "A" and "B" together. They just want to see CTA "A" ... and when that's closed out, the system can evaluate whether CTA "B" is now an issue.
I've built a bionic rule that does the following:
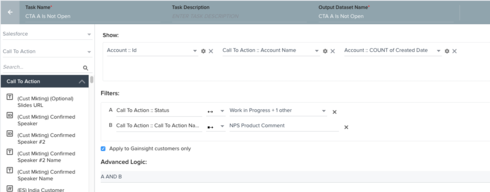
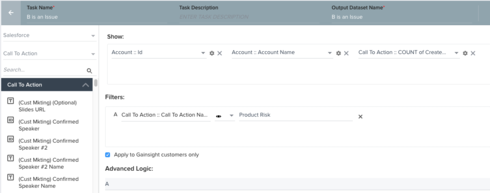
1. Data task identifies all customers where "B" is an issue.
2. Data task identifies all customers where CTA "A" currently exists in Open status.
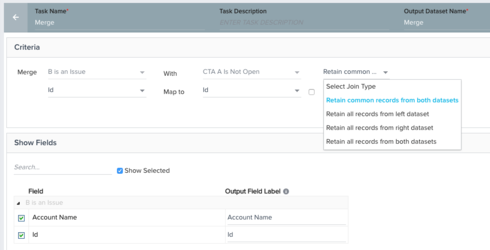
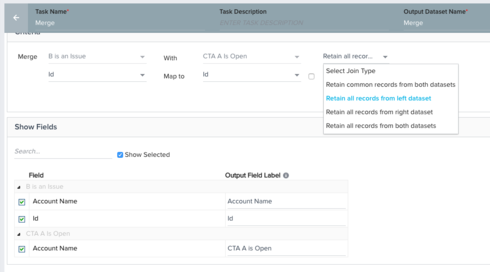
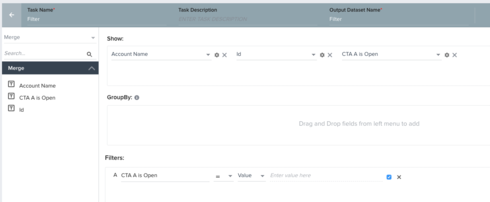
3. Merge task combines the two data sets, keeping only the customers that are eligible for CTA "B" and do NOT already have CTA "A" raised.
Action: Raise CTA "B" for those customers
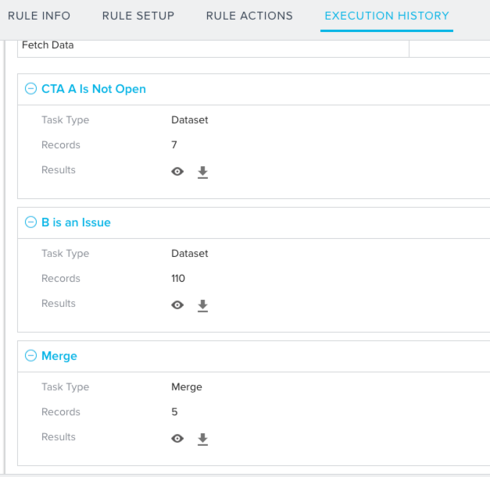
This isn't working. The Action is raising CTA "B" for all customers in Data set 1, so it would seem that my attempt to merge out the ones identified in Data set 2 is failing.
But my overarching question is, Am I approaching this in the best way, or is there a better way?
If this is the best way, perhaps I need help troubleshooting my rule.
Question
Create CTA "A" only if CTA "B" does not exist





Sign up
If you ever had a profile with us, there's no need to create another one.
Don't worry if your email address has since changed, or you can't remember your login, just let us know at community@gainsight.com and we'll help you get started from where you left.
Else, please continue with the registration below.
Welcome to the Gainsight Community
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.