Last Updated On: August 19, 2025
This article guides community administrators to connect to the community data exposed in Gainsight’s Amazon S3.
Overview
Community managers and administrators can enhance their data analysis capabilities by copying data from Amazon S3 to local warehouses. While they can query data directly from the Gainsight Customer Communities (CC) data lake using Business Intelligence (BI) tools such as Tableau or Power BI, copying data offers the added opportunity to join community data with information from various other sources. This capability creates more opportunities for generating comprehensive reports on community usage in the context of company activities, analyzing engagement and developing strategies for improvement.
To achieve this, community administrators must connect to Amazon S3 and copy the relevant data into their local data warehouse. This process allows for seamless data integration and provides richer insights, facilitating more informed decision-making.
Create an S3 Connection in Community
Gainsight CC provides a one-click functionality to simplify and speed up the process of creating an S3 connection. To connect with S3:
- Log in to Control.
- Navigate to Integrations > Apps. The Apps page appears, displaying a list of third-party applications available for integration.
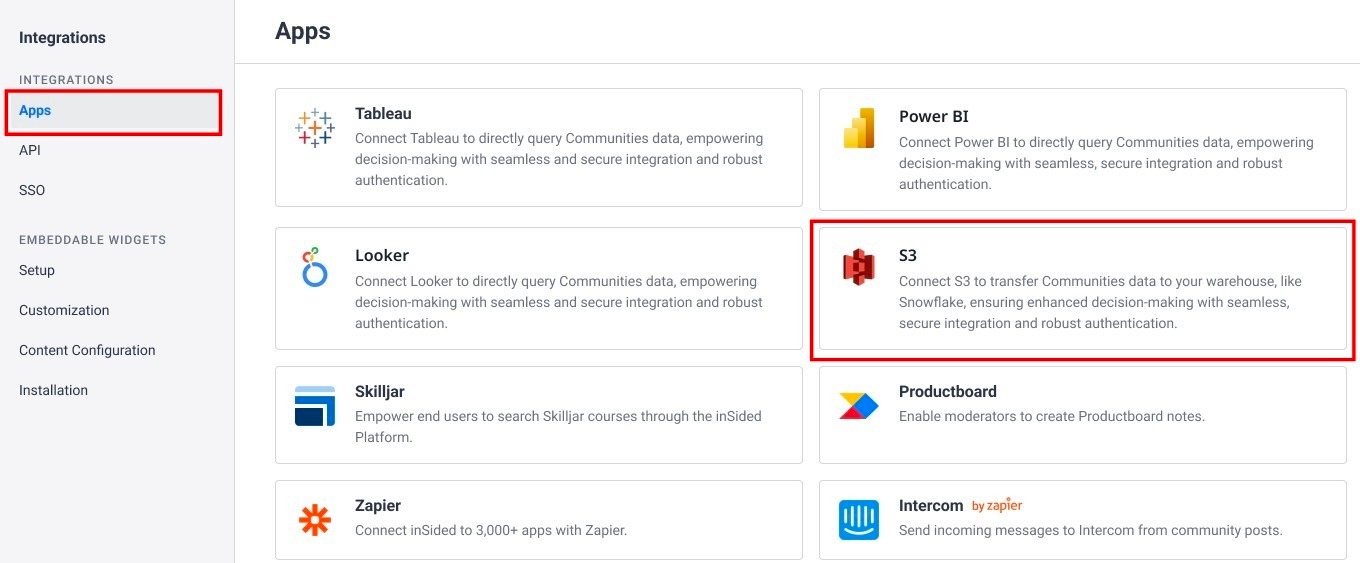
- Click S3. The S3 Connector screen appears.
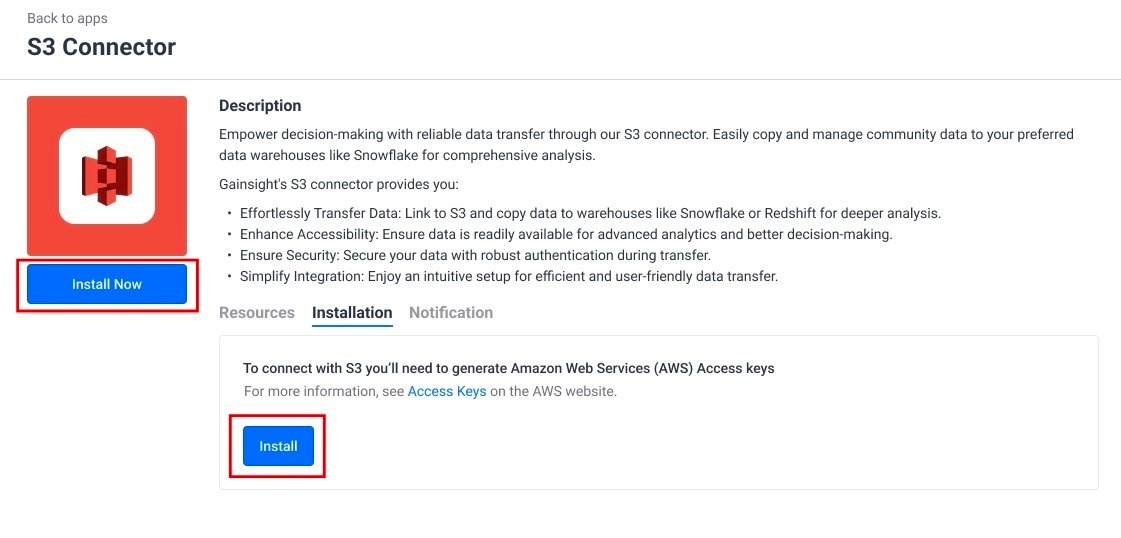
- From the Installation tab, click Install. Alternatively, click Install Now.
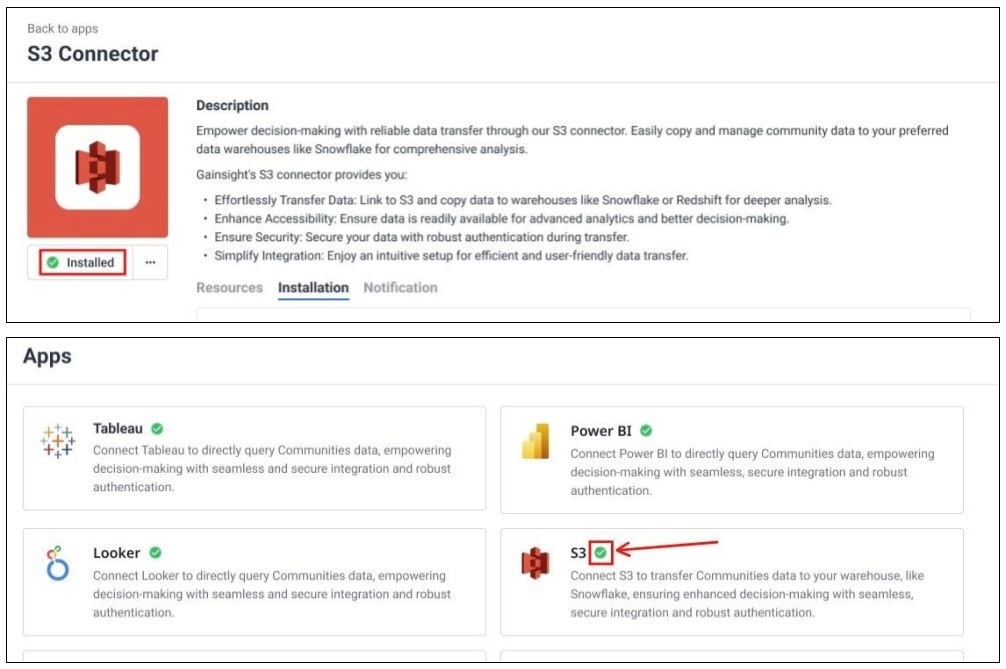
The S3 Connector screen updates to show the Installed status. Furthermore, a green check appears on the S3 connection on the Apps Page.
IMPORTANT:
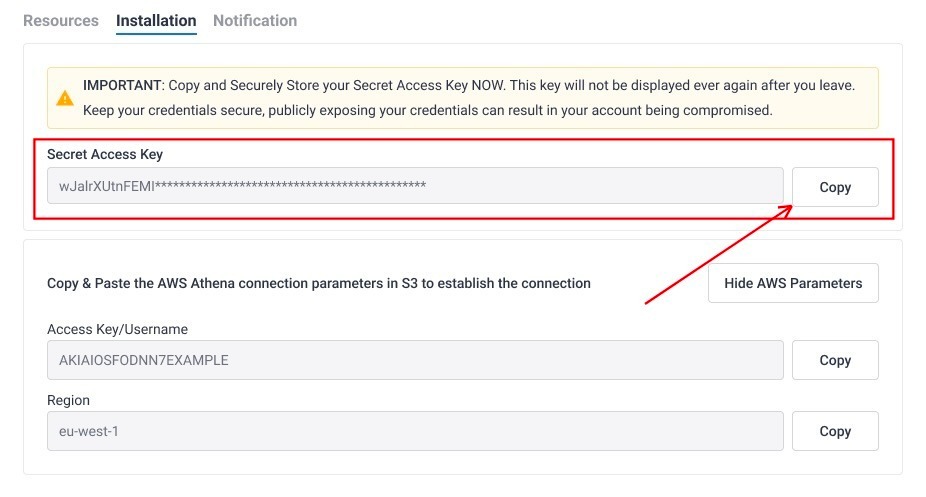
- When the connection is successfully established, Gainsight generates credentials to access S3 bucket with your community data.
- When the connection is created for the first time, Gainsight generates a unique Secret Access Key. We recommend saving this key for future reference, as Gainsight does not store it. If you lose this key, you need to reinstall the connection again to get a new pair of credentials.
Note: When you install the S3 connector, all other data lake connectors, such as Power BI, Tableau, and Looker are automatically installed. You can configure each data lake connector using the same Secret Access Key.
Integrate Data with S3
Once you have your Identity and Access Management (IAM) user credentials to access Amazon S3, you can directly connect to your data or use an external tool for data integration.
To use an external tool, create a new connection and select Amazon S3 as the data source. Once the connection is created, configure the connection with your bucket name and access credentials generated in the integration application.
For more information on how to integrate data using an external tool, visit the official documentation on the tool's website.
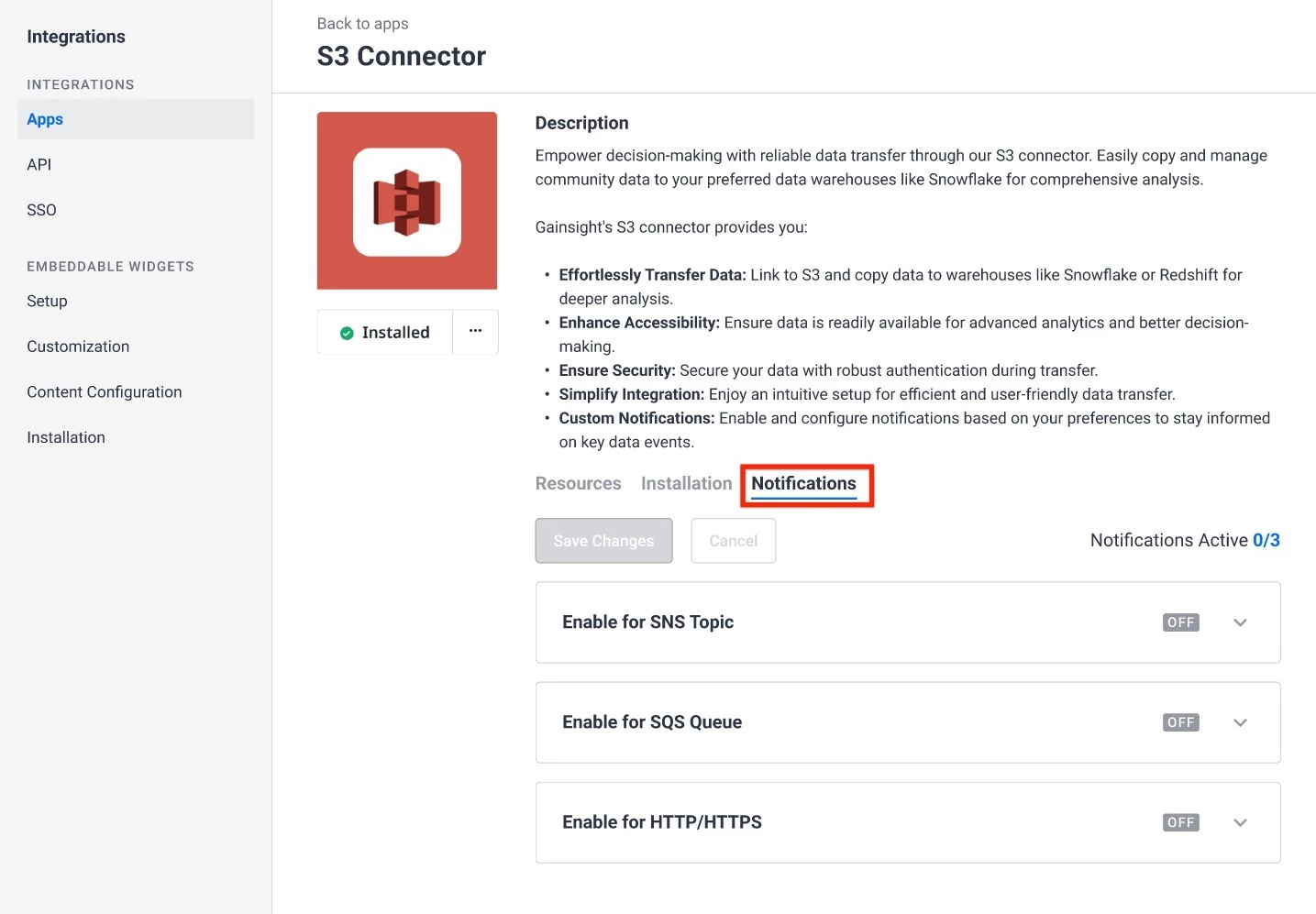
Notifications in S3
Once your S3 Connector is installed, you can configure real-time notifications to help community managers and admins stay updated on data changes.
Gainsight offers three notification options to ensure timely and efficient data updates:
- SNS Topics
- SQS Queue
- HTTP/HTTPS
Note: You can enable one, two, or all three options based on your organization’s needs.
To enable the notifications:
- Navigate to Integration > S3 Connector.
- Click to expand any of the notification options.
- Enter the details required for the notifications.
- Click Save.
Use Community Data
Your community data in the CC data lake is stored in the form of Parquet file objects, namely fact and dimension. Analyzing data in the CC data lake is crucial for gaining insights and making strategic decisions. For more information, refer to the Getting Started with Data Analytics in CC Data Lake article.
- Fact Object - A fact object represents a collection of quantitative information that typically refers to actions, events, or process results. These facts are organized in folders by date, allowing for effective historical analysis. The fact data is refreshed every 30 minutes.
- Dimension Object - A dimension object contains qualitative data that provides context to the facts by describing who or what performed or was affected by the action. Dimension objects store the latest state of the data. Any updates to these objects will overwrite the existing data, ensuring access to the most current information. The dimension data is refreshed every 4 hours.
You can also refer to the Data Catalog and Connectors category and understand different objects and its fields that exist in the CC data lake.
If you have any queries or feedback, please drop an email to docs@gainsight.com or post a reply to this article.


 Supported notification methods:
Supported notification methods: