
Hello Admins!
I got a request to type up a short guide about using Cyberduck as your S3 tool, so here we are!
Cyberduck is a software tool that you can use to access your S3 buckets, whether to import or export your CSV documents. While it’s not the only S3 tool available, we tend to use it because it’s free and works on both MacOS and Windows.
Please note that since I am on MacOS, your application may look slightly different than mine, but all the same steps should apply.
In order to successfully use Cyberduck, the first step will be to install the program from https://cyberduck.io/.
Once installed, launch the program and navigate to the Bookmarks tab.
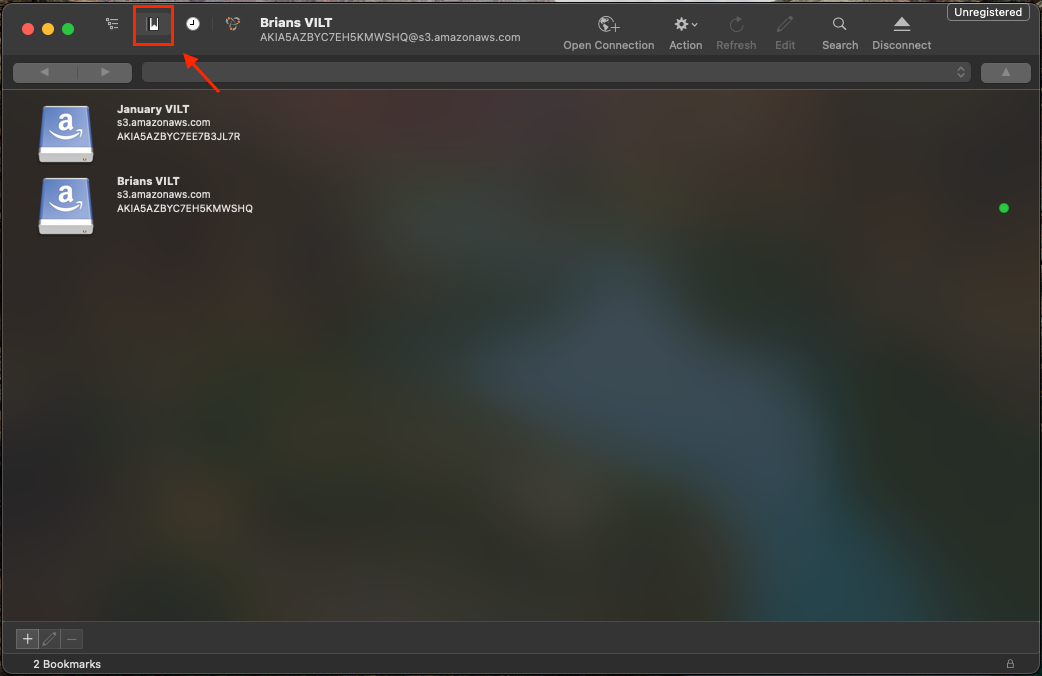
Next, click the + sign in the bottom left corner (or right click → New Bookmark)
On the New Bookmark window that pops up, you will need to edit four things; the connection type dropdown, Access Key ID, Secret Access Key, and Path. It’s also a good idea to change the nickname for easy recognition later on down the road. Your ‘More Options’ may be collapsed by default. If this is the case, just click the arrow to the left to expand it so you can input your path.
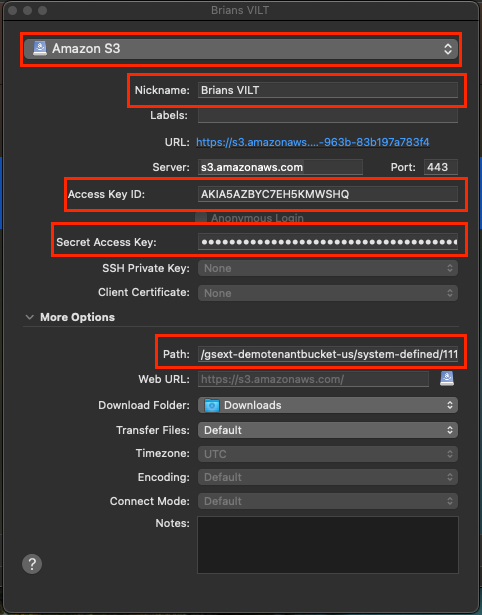
For our purposes, the connection type dropdown will always be Amazon S3.
Your nickname can be whatever makes sense for you.
The other three fields will be pulled from your Gainsight environment.
Navigate to Administration → Integrations → Connectors
Click ‘View S3 Config’ on the upper right of your screen.

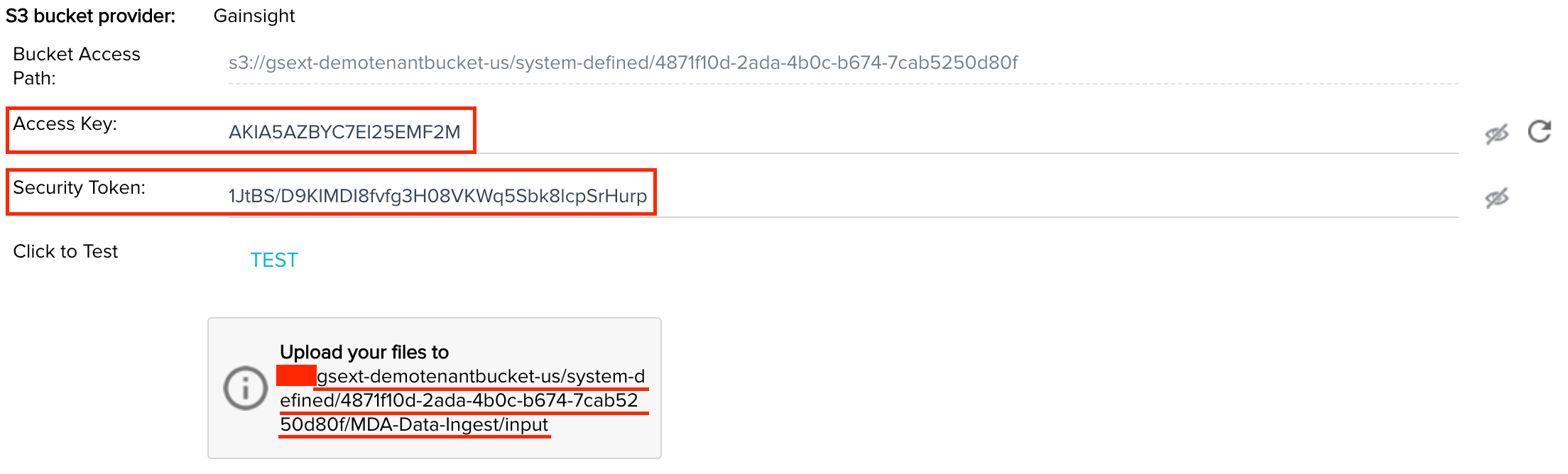
On this new screen you will find the three distinct values you need. Please make sure you only use/distribute this information as necessary. Click the eyeball icons to show your values.
Access Key (Gainsight) = Access Key ID (Cyberduck)
Security Token (Gainsight) = Secret Access Key (Cyberduck)
Upload files to: (Gainsight) = Path (Cyberduck) - When copying this value, start with gsext and copy all the way through input.
Once you have copy and pasted the values from Gainsight into Cyberduck you can close the New Bookmark config window. If everything was successfully input, you should be able to double click your newly created bookmark and see three folders - Input, Archived, Error.
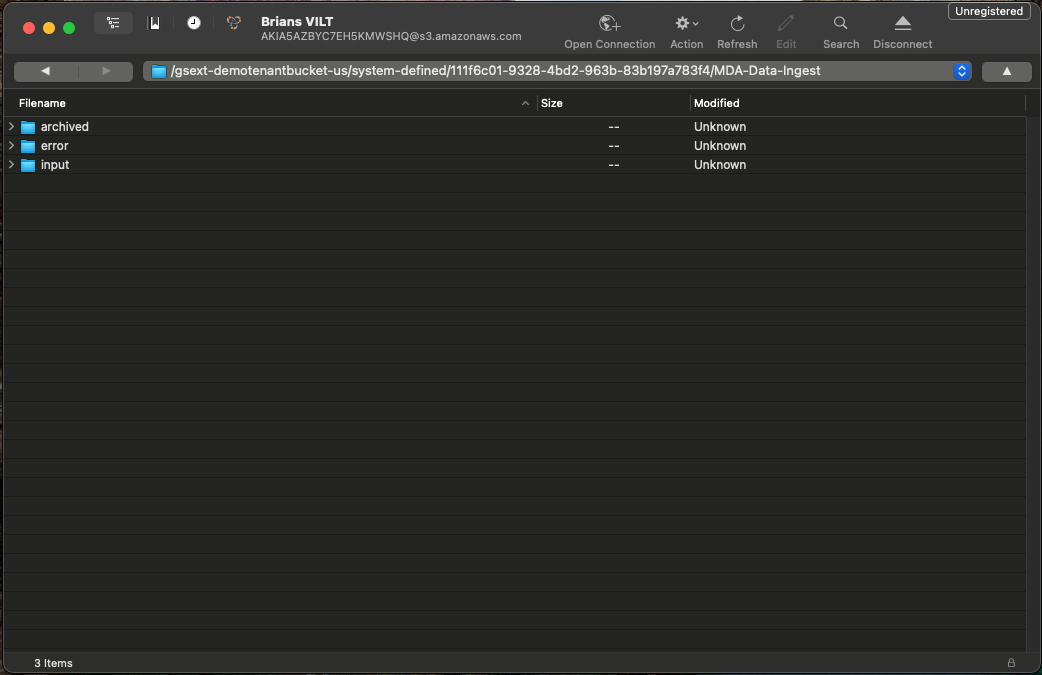
These folders are where your CSV files will live in your S3. Input is used for any CSV files that need to be loaded into your Gainsight instance. Archived will store imported files for you (if you set up your configuration to archive). Error will hold any files that had trouble being ingested.
Hopefully this helps to clarify some things or get you started on you S3 journey if you needed some assistance!
Thank you,
Brian Holmes
