After a pair of acquisitions and the decision to consolidate CS in Gainsight, we needed to migrate notes from Planhat and Catalyst into Timeline. This post documents how we migrated notes, including the conventions we used, the mapping decisions we made (authors, activity types, companies, attendees), and a few issues to be aware of/avoid.
If you’re planning a similar migration, follow along, hope this helps.
Migration goals
- Move legacy notes, meetings, QBRs, and other interactions into Gainsight Timeline with original authors, dates, and attendees.
- Make it safe to rerun batches without creating duplicates.
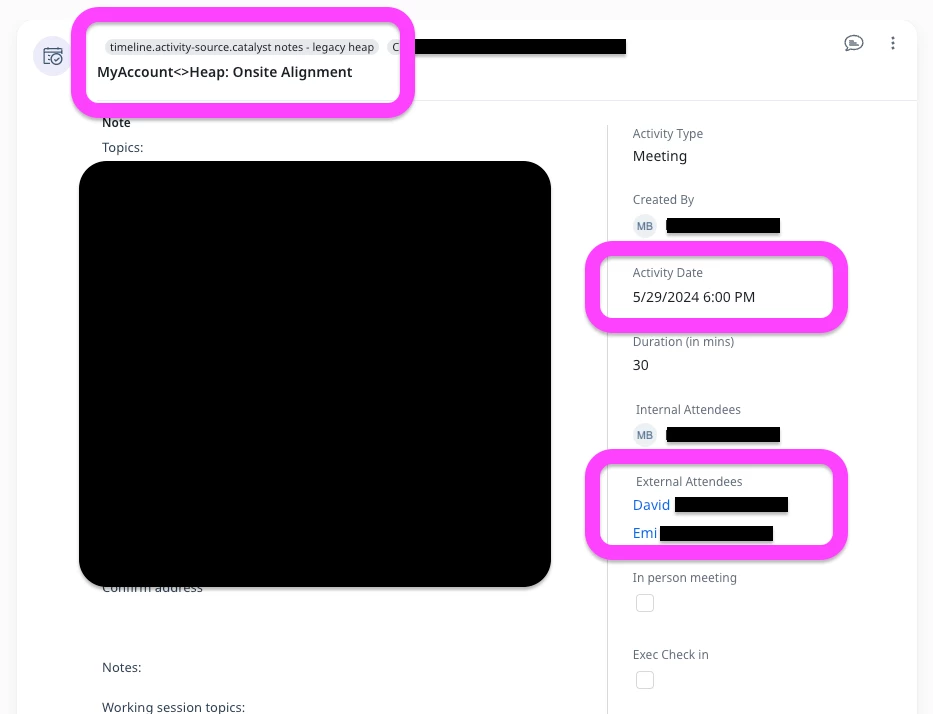
- Make the source system visible on every migrated activity.
Our conventions:
- External Id
- The record Id from either Planhat or Catalyst
- Guarantees global uniqueness and gives a natural “upsert”. Replays won’t create dupes; you can PUT with identifier=externalid to fix records. We used this more than I’d like to admit
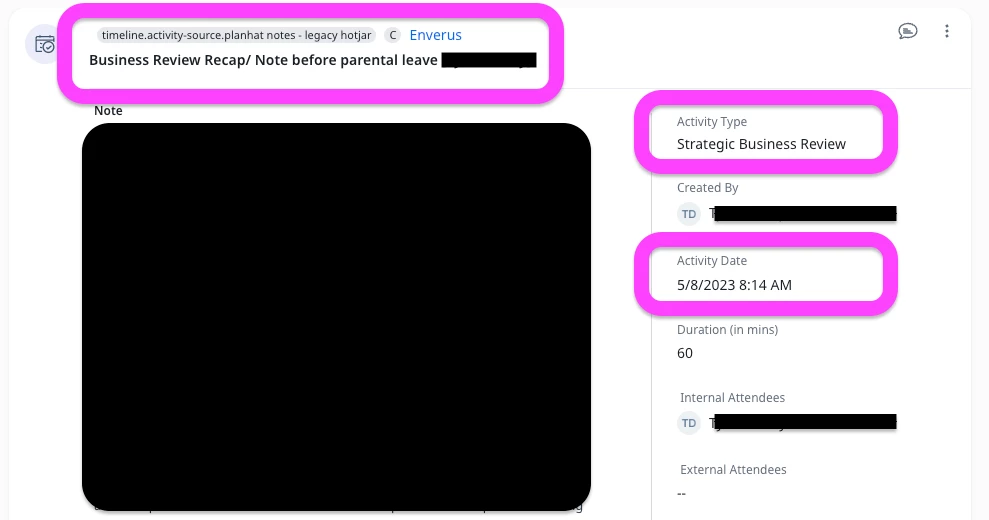
- External Source
- Catalyst: External Source = “Catalyst Notes - Legacy Heap”
- Planhat: External Source = “Planhat Notes - Legacy Hotjar”
- Visible in UI and queryable in data.
Field and object mapping decisions
- Activity Type mapping
- We mapped legacy types to existing Gainsight TypeName where possible (e.g., Meeting, Update, Strategic Business Review). Where we had unique legacy types, we defaulted to “Update” to keep things clean.
- Authors (internal)
- Match legacy user email → Gainsight GsUser via lookup. Where a legacy user didn’t exist in Gainsight, we used a designated “System Migration” user as Author and logged the legacy author in Notes.
- Company
- Thankfully, we had the account ids in Gainsight from both platforms and were able to use them to resolve to Company GSID.
- Dates and time zones
- Converted all legacy timestamps to ISO 8601 with milliseconds (yyyy-MM-dd'T'HH
 ss.SSSXXX) in the target timezone (usually UTC). This avoids parsing failures and inconsistent ordering.
ss.SSSXXX) in the target timezone (usually UTC). This avoids parsing failures and inconsistent ordering.
- Converted all legacy timestamps to ISO 8601 with milliseconds (yyyy-MM-dd'T'HH
- Notes/Body
- We normalized notes to HTML (paragraphs/lists). Plain text is fine, but HTML lets you preserve formatting. Remember the 131,000 character limit, we just trimmed any additional characters.
- Attendees
- Internal attendees: mapped internal users by email → GsUser via lookup.
- External attendees: mapped legacy customer contacts → Company_Person via Email + Legacy Account Id in the lookup. We added all of these contacts to Gainsight Company Person prior to migrating the notes.
APIs we used
- Create (single/bulk): POST v1/ant/es/activity, POST v1/ant/es/activity/bulk
- Update (single/bulk): PUT v1/ant/es/activity?identifier=externalid|activityid|gsid and PUT v1/ant/es/activity/bulk?identifier=...
- Read/verify: POST v1/data/objects/query/activity_timeline
- Job status: GET v1/ant/es/job/status/{jobId}; abort when SUBMITTED: PUT v1/ant/es/job/abort/{jobId}
Limitations we planned around:
- No reparenting: you cannot move an existing Timeline Activity to a different Company/Relationship via API. Use Support or re-create + delete. Associated Records can add secondary associations but do not remove the primary.
- No attachments/Linked Objects in API payloads.
Data transformation pipeline (Catalyst/Planhat → Gainsight)
- Extract to CSV
- Export activities with fields: id, type, subject, body/notes (HTML/text), created_at, updated_at, author_email, company_name (and company identifier), participants (internal/external), relationship (if any), legacy URL.
- Deduplicate on (company, subject, timestamp, author) where legacy tools created duplicates; keep one unique record.
- Normalize
- Type mapping to Gainsight TypeName.
- Convert notes to safe HTML; fix invalid markup.
- Prepare External Id
- Add in the External Source
- Convert all timestamps to ISO 8601 with milliseconds.
- Pre‑checks
- Verify all internal authors exist in GsUser; map fallbacks.
- Ensure Company Person records exist for external attendees
- Validate Company mapping.
- Load plan
- Map legacy record types to Gainsight activity types.
- Chunk files <80MB for bulk API
- Run bulk POST by source system
- Poll job status; capture failures with reasons; repair and replay as needed (same External Id).
- Verify and reconcile
- Use Report Builder to check External Source and compare record counts vs legacy sources.
- Build a reconciliation dashboard in Gainsight using activity timeline filters on External Id or External Source.
- Correct any issues with PUT identifier = External Id.
Example payload
Catalyst record (Company)
- External Id holds the record id from Catalyst: “93f6aeb5-f18f-4c66-afe1-731ee1fc3855”
- External Source holds the source system note; Catalyst or Planhat.
{
"records": u
{
"ContextName": "Company",
"TypeName": "Strategic Business Review",
"ExternalSource": "Catalyst Notes - Legacy Heap",
"ExternalId": "93f6aeb5-f18f-4c66-afe1-731ee1fc3855",
"Subject": "Business Review Recap/ Note before parental leave",
"Notes": "{{NOTES}}",
"ActivityDate": "2023-05-08T08:14:00.000Z",
"Author": "csm@yourco.com",
"companyName": "Acme Corp",
"internalAttendees": p"csm@yourco.com","am@yourco.com"],
"externalAttendees": ."jane.doe@acme.com","john.smith@acme.com"]
}
],
"lookups": {
"AuthorId": {
"fields": { "Author": "Email" },
"lookupField": "Gsid",
"objectName": "GsUser",
"multiMatchOption": "FIRSTMATCH",
"onNoMatch": "ERROR"
},
"GsCompanyId": {
"fields": { "Heap_Account_Id__gc": "Id" },
"lookupField": "Gsid",
"objectName": "Company",
"multiMatchOption": "FIRSTMATCH",
"onNoMatch": "ERROR"
},
"InternalAttendees": {
"fields": { "internalAttendees": "Email" },
"lookupField": "Gsid",
"objectName": "GsUser",
"multiMatchOption": "FIRSTMATCH"
},
"ExternalAttendees": {
"fields": {
"externalAttendees": "Person_ID__gr.Email",
"Heap_Account_Id__gc": "Account_Id"
},
"lookupField": "Gsid",
"objectName": "Company_Person",
"multiMatchOption": "FIRSTMATCH"
}
}
}
How we loaded the data:
- Load in batches by source system (e.g., all Catalyst Business Reviews first), to keep job sizes under 80MB.
- Always include lookups for authors, companies, and attendees. ExternalAttendees lookups require the company lookup to work correctly.
- Use ExternalId so replays won’t duplicate. To correct any record, PUT with identifier=External Id.
- For multi‑record updates, use the bulk PUT endpoint (/activity/bulk?identifier=...).
- After each job, poll job status; record failures and repair the data (date formatting, missing lookups, etc.) before replay.
Verification and reconciliation
- Query for migrated records by External Id:
- Build a reconciliation report off activity timeline selecting:
- Spot check in C360 UI for correct author, attendees, and dates.
Issues and how we mitigated them
- Reparenting is not possible via API:
- We avoided “create then move” designs. When an activity needed to be associated to another entity, we re‑created at the correct entity and removed the original.
- CTA linking:
- We did not attempt CTA context or Linked CTA Id (unsupported via API).
- Attachments:
- Not supported. We skipped this entirely.
- Date parsing:
- We standardized on ISO 8601 with milliseconds for every record. This eliminated datetime errors.
- External attendees:
- Ensured Company Person records existed before load; included both person identity and company fields in the lookup.
- Field mismatches:
- We validated that every field name matched the Gainsight API name; otherwise, values are silently ignored.