I'm trying to use the outer join "Retain all records from both datasets" option in a Merge task in a Bionic Rule that is bringing together data from three separate MDA tables. I want to merge on the field that corresponds to the Email Address of the client. Not all clients are represented in each set of data (ie - in this case there is no one table that includes all clients).
However, because I can't include both "User Email" and "User Email" in the Show Fields,
some of the email addresses are getting left off of the results and I'm left with data points (number of downloads, for example) that have no contact identification information.
I therefore can't load this data to the MDA table using this field as an identifier.
When I rename the fields to "User Email" "User Email 2" "User Email 3", etc, I am able to view the email for all results however I'm not sure of the best way to load this to the MDA table, as I now have multiple fields containing the email address.
Looking for some help or advice on how best to perform Outer Joins or to merge data when using the same field to merge on and identify data.
Solved
Outer Join (Retain All Records From Both Datasets) Question

Best answer by dan_ahrens
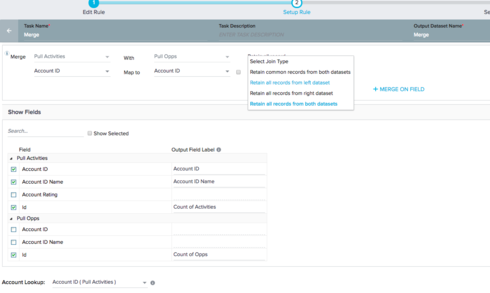
The issue you're running into with that merge is that if a record does not have any activities but does have opportunities, it will appear in your "pull opps" fetch, but not in your "pull activities" fetch.
Then when you merge, you bring in the count of opportunities, but don't bring in the Account ID or Account ID name (they are unchecked in your Show Fields area.
The way around this is to change the output name for Account ID and Account ID Name so that records that do not exist in both fetches still retain their account ID and name.
Another way to skin this would be to do a third fetch of all accounts. Then do two merges, first merge has the "all accounts" fetch in the left dataset with a left join merged with "pull activities" - write the count of activities to an output field.
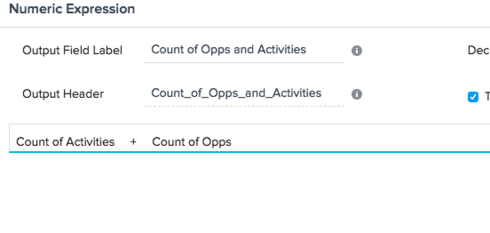
Then merge this task with your "pull opps" (in the right position) using a left merge on the output from the first merge. Bring in count of activities and add count of opps in your output.
That will give you a record for each account that has a column for "count of activities" and "count of opps"
Then when you merge, you bring in the count of opportunities, but don't bring in the Account ID or Account ID name (they are unchecked in your Show Fields area.
The way around this is to change the output name for Account ID and Account ID Name so that records that do not exist in both fetches still retain their account ID and name.
Another way to skin this would be to do a third fetch of all accounts. Then do two merges, first merge has the "all accounts" fetch in the left dataset with a left join merged with "pull activities" - write the count of activities to an output field.
Then merge this task with your "pull opps" (in the right position) using a left merge on the output from the first merge. Bring in count of activities and add count of opps in your output.
That will give you a record for each account that has a column for "count of activities" and "count of opps"


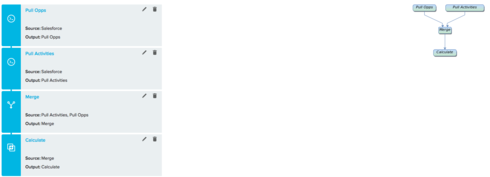
Sign up
If you ever had a profile with us, there's no need to create another one.
Don't worry if your email address has since changed, or you can't remember your login, just let us know at community@gainsight.com and we'll help you get started from where you left.
Else, please continue with the registration below.
Welcome to the Gainsight Community
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.