
In our continuous endeavor to improve our rules and data processing platform, over the last two quarters we have done many changes which have significantly improved the average wait times across our customer base for rule runs. This post shares a brief on the changes we have done and the impact it has had on execution times.
We have moved rules into our micro service architecture and have also scaled our infrastructure to meet the growing number of data processing executions. Additionally, we have also worked on improving context switching and micro batching of jobs resulting in reduced wait times for the rule to be picked up for processing. Because of these changes, we were able to increase the parallel rule executions for our customers.
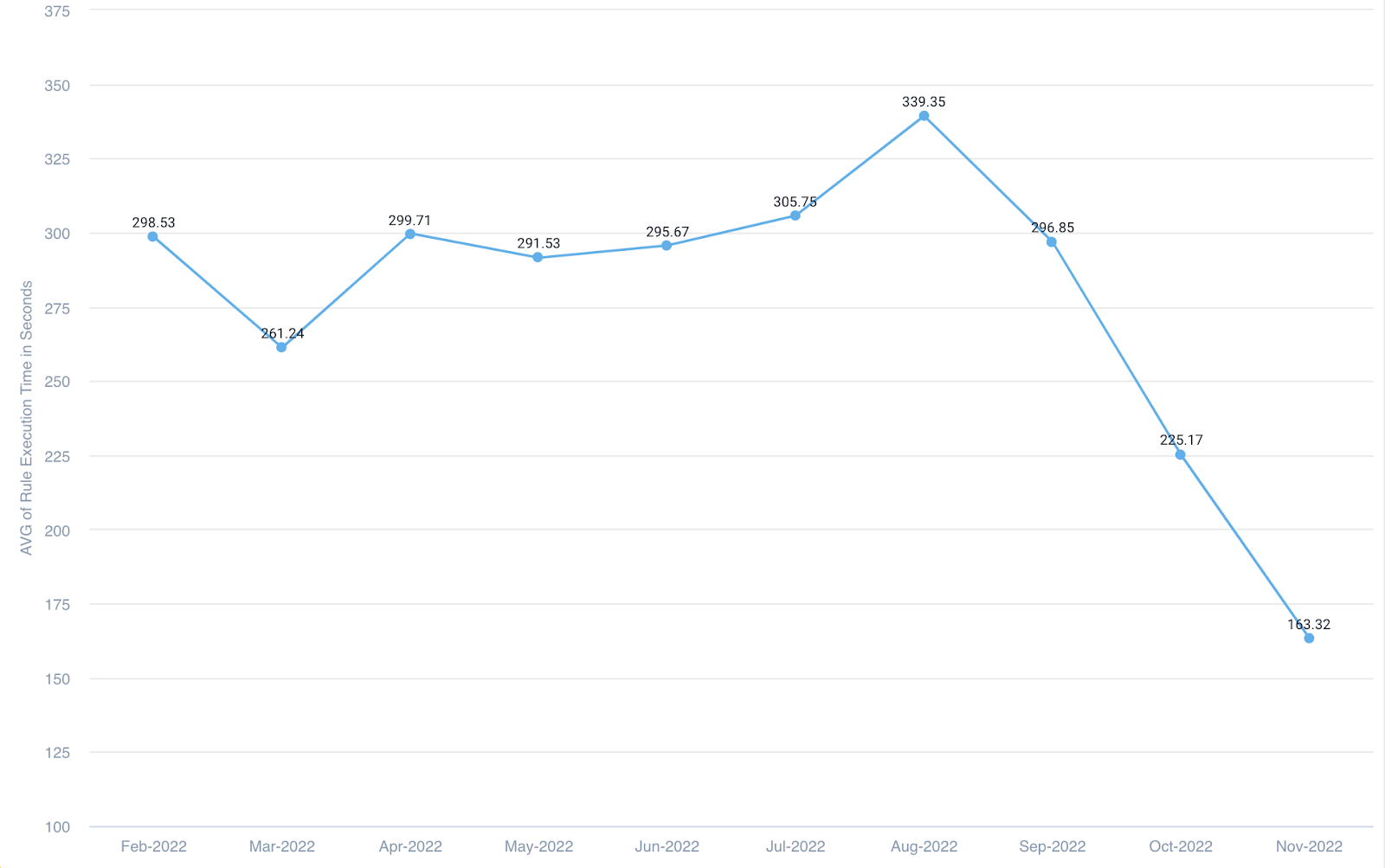
We pushed these changes in a phased manner starting early September 2022 and completed in October 2022. We have seen 51.87% improvement in average rule execution times from its peak in Aug 2022. Rules execution time is calculated as the time difference between when a rule was added to the queue to when it completes execution.
Here is a visual representation of the average execution times for rules since Feb 22:
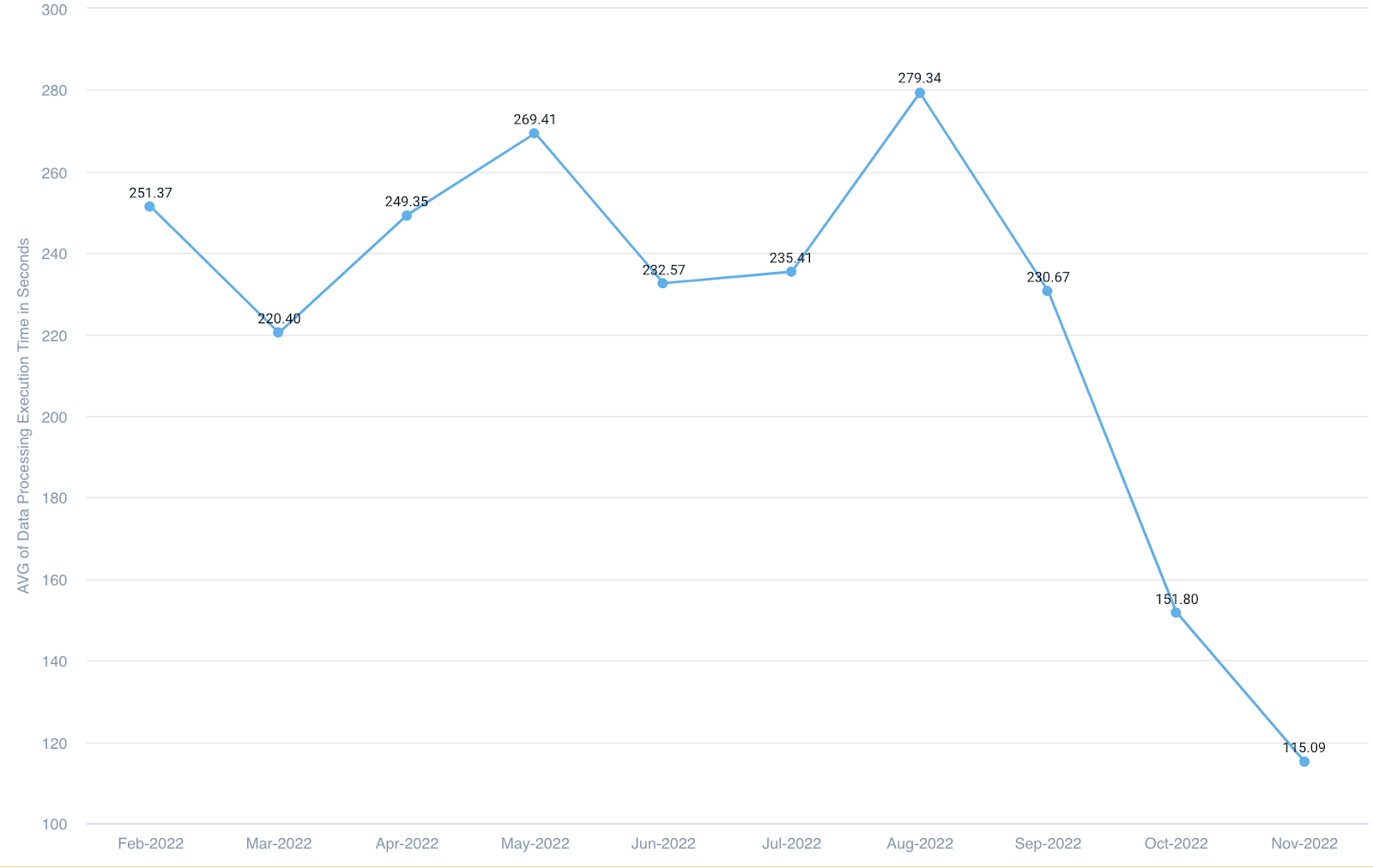
Majority of these improvements were in the wait times of the data processing stack which is responsible to run the data preparation such as extraction, transformation, and merges.
Here is a visual representation of the average execution times for the data processing portion of rules since Feb 22:
Similar to Rules, other product areas in Gainsight like Data Designer, JO, connectors, and Adoption Explorer all use the distributed data processing stack. Improvements in the data processing execution times also contributed to better execution times for all these product areas as well.


