If styling is applied to a sentence in the engagement (bold text) text strings are truncated into different lines when exporting the language XLIFF file.
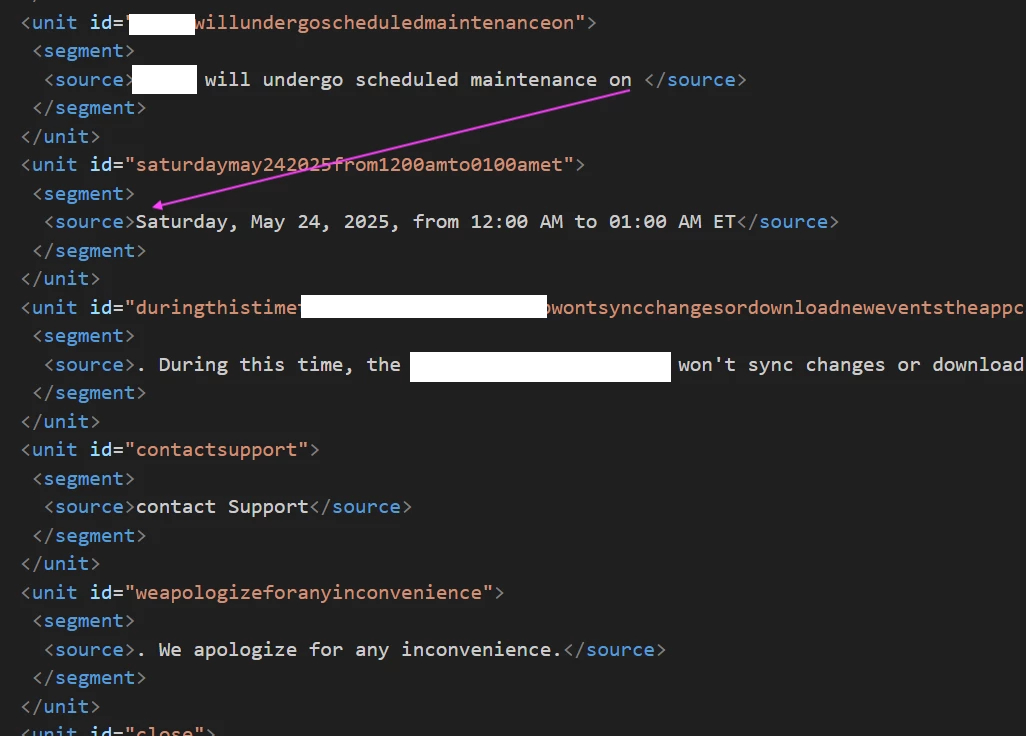
Truncating sentences is bad for localization as different languages require different sentence structure/order. For example, for some languages the bold text could be at the beginning of the sentence rather than in the middle.
At the moment we need to manually adjust the placement of bold and regular text in the downloaded XLIFF file, and it’s wasting a lot of our time and patience.