
Summary
This article breaks down the "it depends" framework for choosing between Data Designs (DDs) and one-off queries as your Journey Orchestrator audience source. It explores how to use DD Templates for standardization and Dynamic JO Filters for easy testing and targeting, a topic I covered in my Pulse Academy Live (PAL) talk at Pulse 2025. The post weighs the pros and cons of each approach, contrasting the easy, centralized updates of a DD with its high-risk potential as a single point of failure and a source of sync-timing conflicts. Ultimately, it provides a framework for when to use a safer one-off query (for high-stakes programs) versus a centralized DD (for low-risk, multi-use audiences).
Overview
If you've spent any time in Journey Orchestrator—especially if you cut your teeth on Advanced JO—you know the frustration. You need to tweak one tiny piece of audience logic, and suddenly you're cloning an entire program just to edit the source query. It's a time sink, and it clutters your instance with duplicates that make you want to scream into the void.
Enter Data Designs (DDs) and Dynamic JO Audience Filters. They promise a better way: simpler audiences, easier updates, and less redundant work. And honestly? When used right, they deliver.
But here's the thing: a "DD-first" approach isn't a silver bullet. Go all-in without thinking it through, and you'll trade one set of headaches for another—sync timing nightmares and single points of failure that can take down multiple programs at once.
When do you use a Data Design, and when do you use a query? "It depends" is the only answer.
Details
The Building Blocks: DD Templates
Data Designer Templates are your secret weapon for standardization. Think of them as reusable Lego sets—once you've built your "Account Team Info" merge or your "Active User Status" logic, save it as a template. Pull it into new Data Designs as needed. No more rebuilding the same structure from scratch every single time.
The real power move? You can pull DD Templates into single-use queries. You get the standardization of your core logic with the safety and independence of a one-off query.
See the screenshots below from PAL where I merge together two separate DD template to build a multi-source query without reinventing complex logic. Note the naming conventions (something I referenced previously). Easily understood names make it far easier to follow along, even if you don’t have visibility into the individual steps.
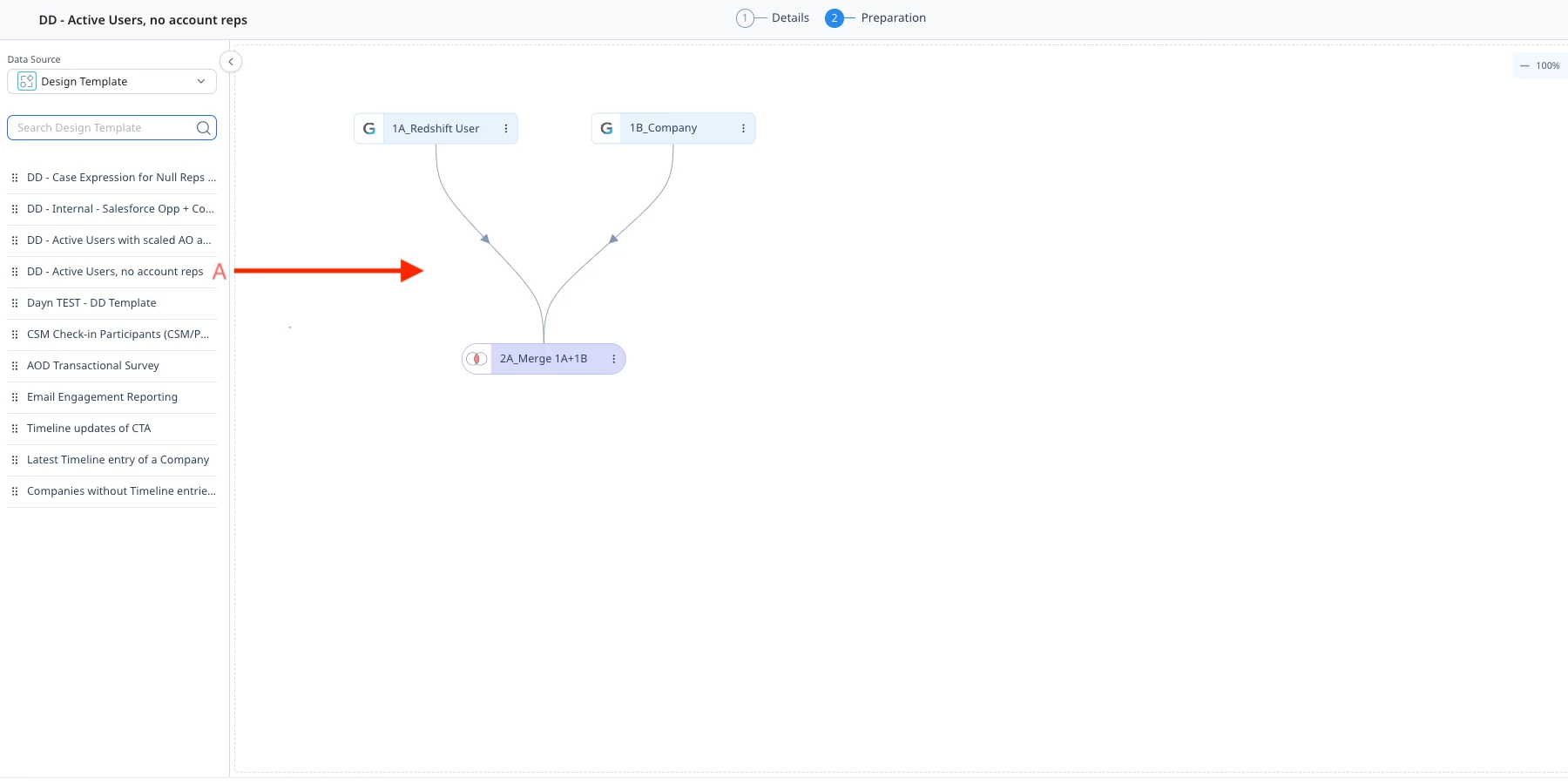
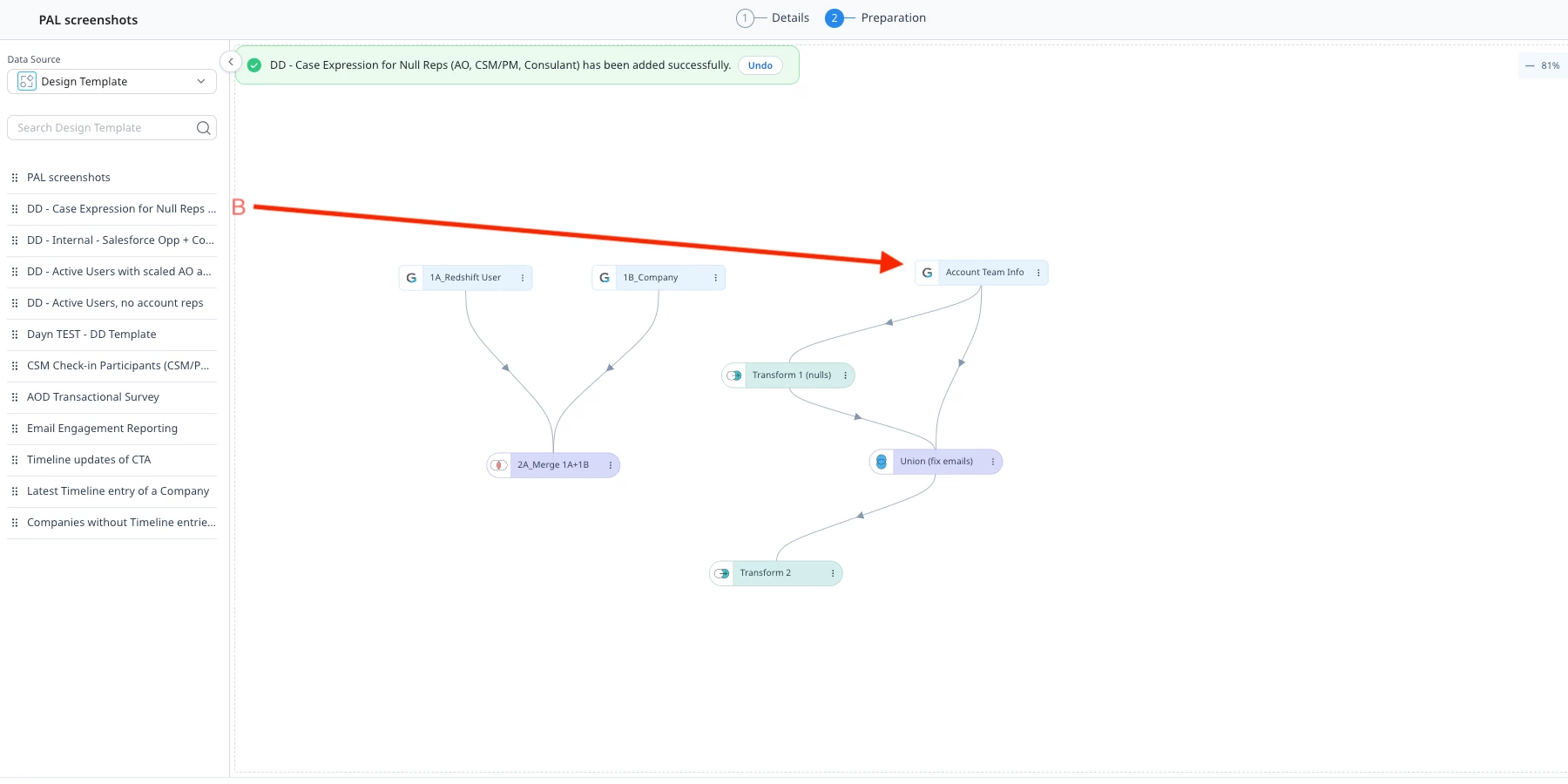
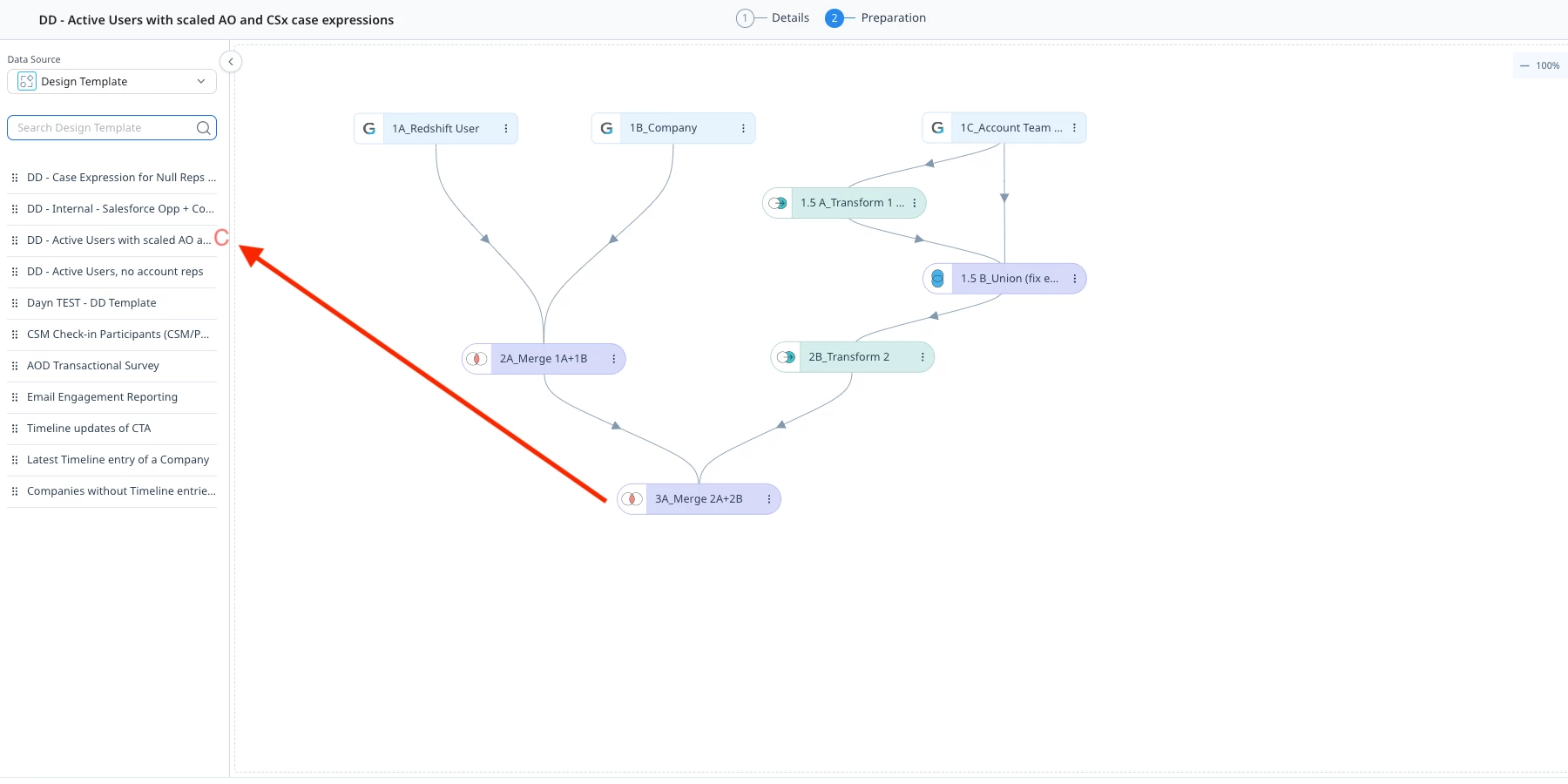
The Great Debate: Centralized DD vs. One-Off Query
This is where the rubber meets the road. For ongoing, repeatable programs, centralized Data Designs offer serious advantages:
One source, many journeys. A single DD can power multiple JOs, which means one sync schedule instead of ten. Less system load, fewer scheduling conflicts, and when you need to update that audience logic, you do it once. The changes flow downstream to every program using it.
Sound perfect? Not so fast.
The dilemma of a single point of failure is a real problem. If your master DD fails—or worse, runs with bad data—it doesn't just break one JO. It breaks every JO depending on it. Your critical renewal communication and your "thanks for being awesome" email both go down together. A one-off query might be locked to its program, but when it fails, the damage is contained.
Then there's the Rule Engine traffic jam. Your Ops team is already juggling scorecards, data syncs, CTAs, and a dozen other scheduled processes. When you add a massive master DD to the mix—especially one pulling from Data Spaces—you've just thrown a semi-truck onto an already crowded highway.
Ask yourself: Does your DD sync finish before the JO tries to pull the audience? If your DD runs at 2:00 AM and your JO fires at 1:55 AM, congrats—you're working with yesterday's data. Or the whole thing just fails. A simple query runs with the JO, so you sidestep this timing mess entirely.
Dynamic Filters: The Gamechanger
This is where it all clicks. Dynamic JO Audience Filters are what make the "broad DD + specific targeting" approach actually work.
Instead of building hyper-specific Data Designs for every use case, you build one broad DD (like "All Active Users") and apply filters at the JO level:
- JO 1 Filter: Region = 'North America'
- JO 2 Filter: Product Usage = 'High'
- JO 3 Filter: Survey Response = 'Detractor'
All three JOs run off the same DD. One sync schedule. One place to update the core logic.
But my favorite use? Testing. Drop in a filter for Email = 'dayn@mycompany.com' or Company Name = 'Test Account' and you can safely test your entire journey with real data before going live. There’s no need to tweak the Data Design itself. When you're ready, remove the filter and flip the switch.
*Note – this is also a good way to prevent any NET NEW participants from entering an active program while allowing existing participants to complete it. Change the Account ID to a value that will never be true, and no new participants will qualify to enter.
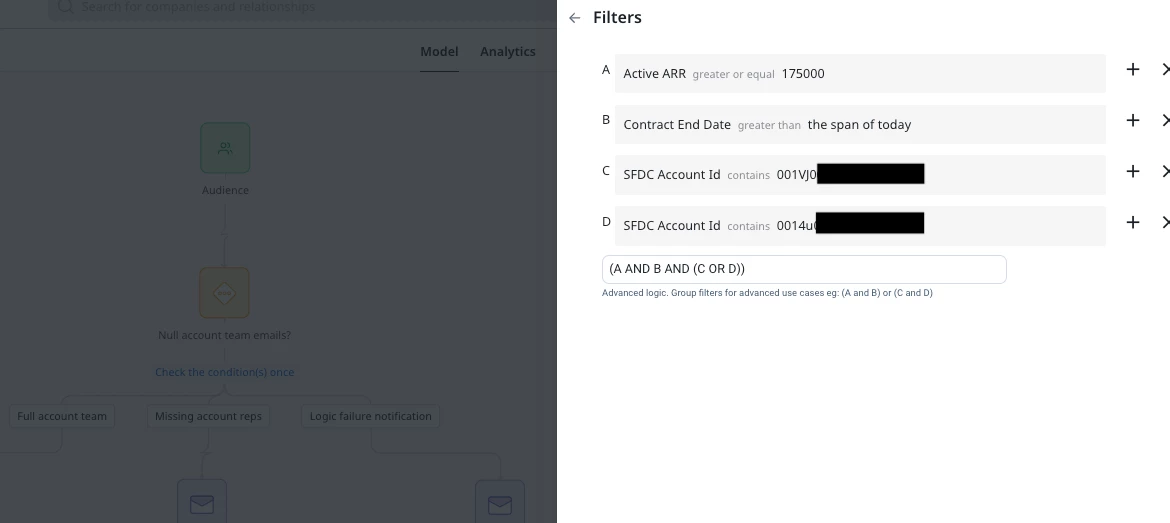
My “It Depends” Framework
Use DD Templates everywhere—both in other DDs and in single-use queries. Standardize your core logic.
Use a Centralized DD + Filters when:
- You've got multiple low-stakes programs using the same base audience
- You're willing to monitor and coordinate sync schedules
- Easy, centralized updates outweigh the single-point-of-failure risk
Use a One-Off Query (ideally powered by a template) when:
- It's a high-stakes, must-not-fail program (renewals, critical EBRs)
- The audience logic is truly unique and won't be reused
- You can't risk sync timing conflicts with other rules or JOs
The Bottom Line
There aren’t any hard and fast rules here. Don't build everything as a centralized DD just because you can. Don't default to one-off queries because "that's how we've always done it." Pick the best tool for the job and your level of risk tolerance.
To my fellow admins: How are you balancing this? Have you built a master DD that's become a single point of failure? When do you always choose a query over a DD?
This post is part of my JO-focused series. Check out my earlier post on planning your first JOs for more of my thoughts on scalable operational processes. I’m planning future posts on documentation, benchmarking, and general dynamic JO best practices.

